Incrementality Testing
An introduction to Design & Implementation of good Incrementality testing programs
Why Experiments ?
Experiments includes a set of tools and techniques to ascertain the true Incremental Contribution of media channels / tactics / campaigns. Experiment is also the best approach to establish Causality between media interventions and the outcome that it drives.
Experiment is considered the Gold Standard of Measurement
A simplified description of the approach of Experiment is to look at it as a way to create a Control and a Treatment group of Test Units ( refer to "Level" in the table below to understand what Test Units are) Intervene with the treatment group (this intervention happens through spend changes, pricing changes etc...) with some treatments and compare the outcomes between these groups and compute the lift within certain levels of (acceptable) statistical significance.
This is achieved by running "Randomized" and "controlled" tests (RCT) at various levels.
Randomization can happen at 3 levels
| Level | Test Type | Description | |
|---|---|---|---|
| 1 | Geography | Geo Test | Pick a group of market clusters with control and treatment geographies in such a way that they are similar to one another in some aspects. Intervene in the treatment cluster and measure the impact of the intervention over the testing period |
| 2 | Time Period | Spend Test | Compare two different time periods after adding "right" variations into the spend. Compare the outcome across these time periods to understand the impact of the Variations |
| 3 | Segment | Split Test | Pick a segment of first party profiles, randomly separate them to control and treatment groups with right sizes. Expose the treatment group with ad campaigns that needs testing. Compare the outcome from control and treatment groups over the test period and compute the lift |
Though experiments are considered the best approach to measuring incrementality, adopting experiments at scale in marketing context poses some practical (& statistical) challenges.
These are the 3 biggest challenges in running a good experiment
- Randomisation
True randomisation is hard to achieve in marketing - whether that be for different groups of profiles, geographies or periods in time. We need to adopt advanced algorithms for customer segmentation and lookalike, market matching & smart spend levels and period selection - Control
Marketing environment is influenced by a number of variables. Every user is exposed to the "Brand" continuously through different media and channels. When a test is underway, we need to control for two things- Control group is kept away from any influence of the intervention
- The impact of all the "other" variables should be kept constant or with limited variations during the flight of experiment
Refer the diagrams below to understand more about the "Control Problem"
- Ad Stock Creep
The period before and after the Test Period continue to influence and potentially corrupt the test period. The ad stock of the pre-test period will creep into your testing window. Should we add a "cooling period" between pre-test period and test period. What should be the ideal gap of this cooling period and what's the best way to control for this period.
At what point will we stop testing and adopt the result. The intervention on the test period will continue to create impact even after we close the testing window. How can we adjust for this ad stock effect ?
Example of a Test Setup
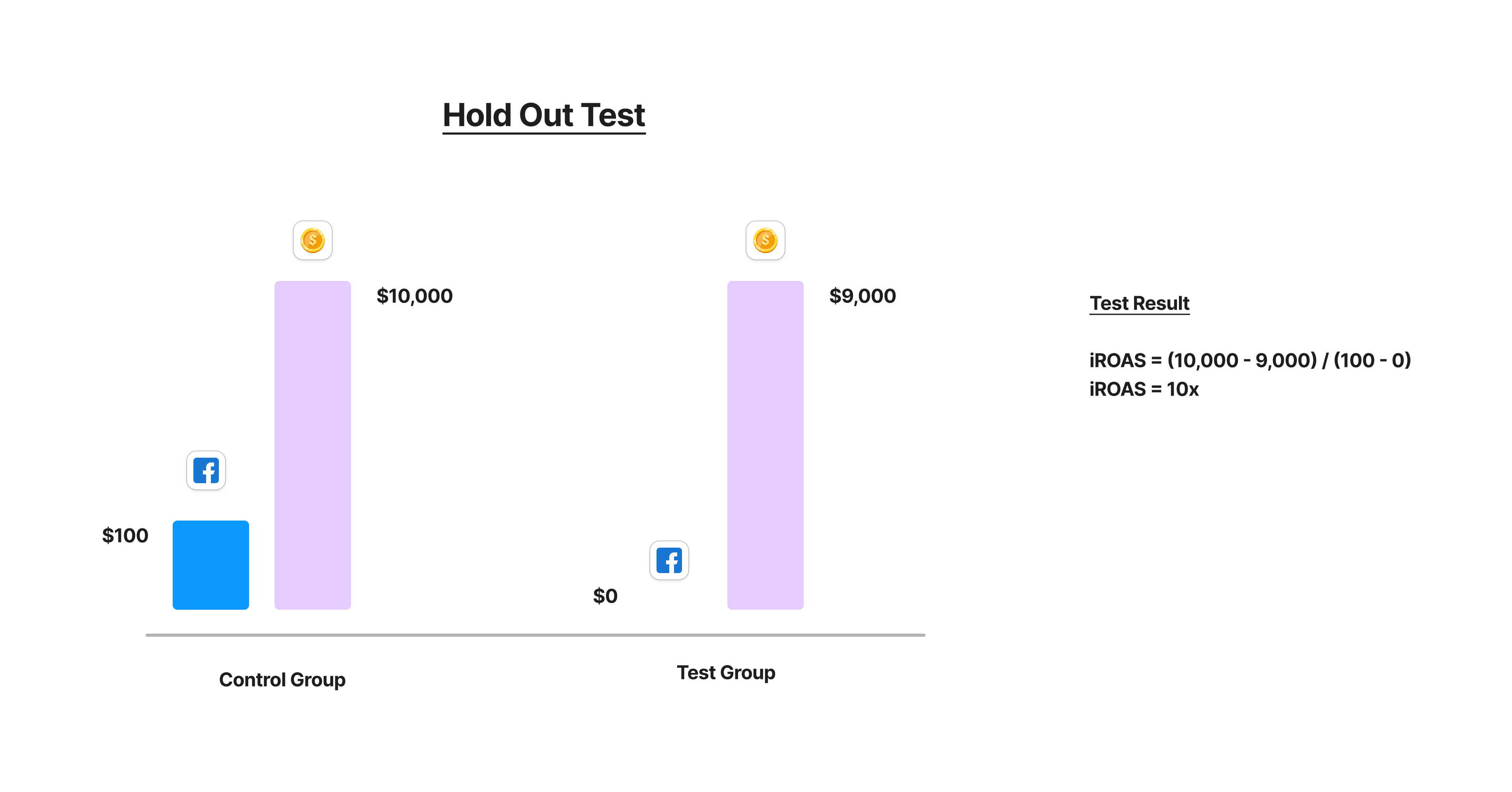
What we see above is an (over)simplified view into Experiments. A more realistic view of all the complexity will look like this
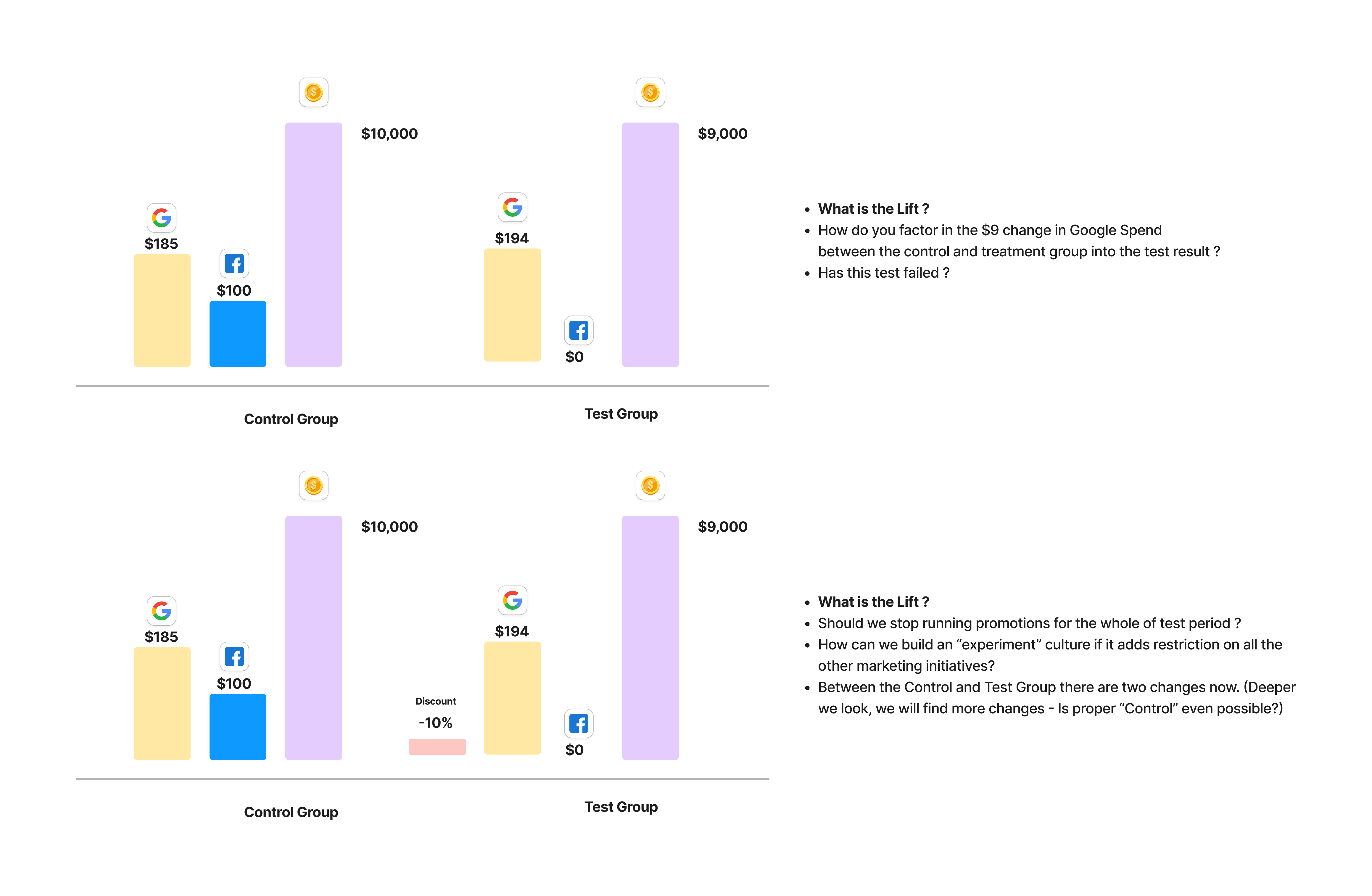
Because of the challenges posed by Randomization, Control & Ad Stock Creep, marketing experiments are different from the traditional experiments run in laboratory settings. While we compute the impact of the interventions over control and test group, we also need to account for the confounders, approximate for ad stock and saturation of channels and also model for other variations to get accurate test reads.
Keeping all of this in perspective, marketing experiments, in reality, are at best quasi-causal in nature.
There are multiple approaches to quantify for causal impact between treatment and control groups. Some of the popular ones are : Difference in Difference, Synthetic Control Method, Regression Discontinuity and Ridge Regression.
Next learn about Lifesight's Experimentation Framework to run geography level incrementality tests here
Updated 8 months ago