Unified Marketing Measurement
Unified Marketing Measurement (UMM) is the practice of running Marketing Mix Modeling, Incrementality Testing, and Causal Attribution together as one orchestrated system - on a single data foundation - so that each method strengthens the others, rather than treating any one of them as a complete answer on its own.
For decades, marketing measurement has been sold as a destination: the one model, the one platform, the one number that finally settles what your spending is worth. That number does not exist - not because the math is immature, but because the underlying problem (inferring the causal, incremental value of marketing from incomplete data about human behavior) has no single exact answer that holds across time and context, only a distribution of plausible ones. A method that claims to have abolished that uncertainty has not solved the problem; it has hidden it.
UMM starts from the opposite premise: several imperfect reads, each with a different blind spot, arranged so they keep one another honest.
Why a single method is never enough
Each of the three major approaches is a genuine advance in service of a real question. Each becomes a liability the moment it is asked to answer every question at once.
➡️ Attribution wants to follow the customer. The instinct is sound, but a credit-allocation question is not a causal question. Knowing that a customer touched an ad before buying tells you nothing about whether they would have bought anyway. Attribution turns "what caused this sale?" into "who gets the credit for this sale?" - two questions that only look alike.
➡️ Marketing Mix Modeling wants to model the whole business at once. Also sound, since marketing happens in aggregate, alongside price, promotion, seasonality, and forces no tracking pixel will ever see. But MMM rests on thin, aggregated data, and where the signal runs out it leans on priors, transformations, and modeling choices the buyer rarely sees.
➡️ Incrementality Testing wants to prove it. Most rigorous of all - run a controlled test, measure the lift, let the data speak. But a marketing test runs in a live market that will not hold still, has no true placebo, and ends long before the carryover effects do. The lift is real, but it is a single point-in-time read of a relationship that is always moving.
None of these methods is lying. Each is simply a partial answer being sold as a complete one - over-claiming in exactly the dimension where it is strong, and going quiet in exactly the dimension where it is weak.
The first and most expensive mistake in measurement is not the choice of any particular method. It is the belief that a single method is sufficient.
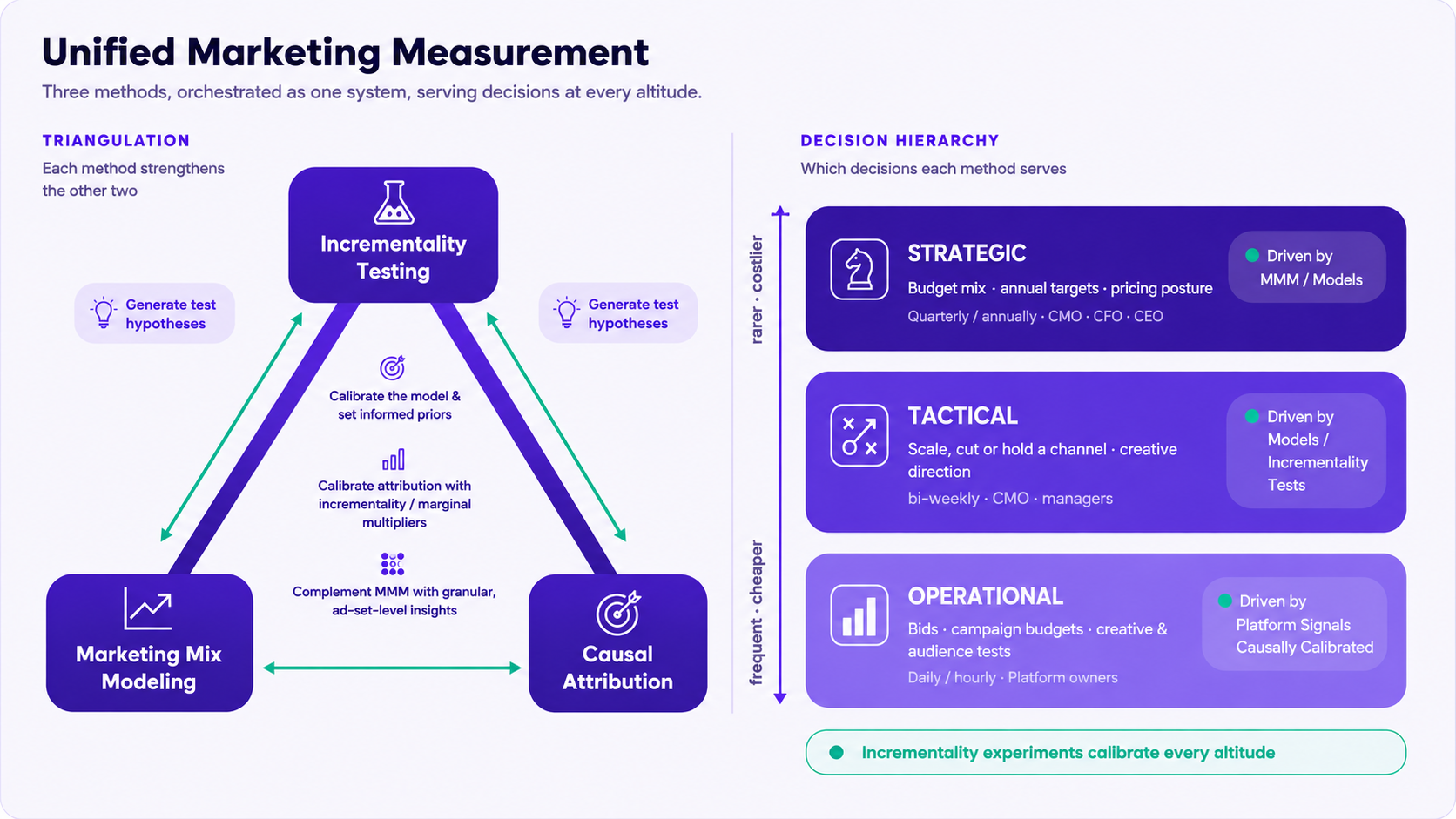
Measurement serves decisions, and decisions come at three altitudes
Before choosing a method, it helps to ask what you are choosing it for. Marketing decisions sort themselves into three levels, and a method that is perfect for one can be useless for another.
| Level | Decisions | Cadence | Owner | Best served by |
|---|---|---|---|---|
| Strategic | Budget mix across channels, annual targets, profitability goals, pricing posture, big bets | Quarterly / annually | CMO, CFO, CEO | Marketing Mix Modeling - the only method that sees the whole board and can forecast |
| Tactical | Scale, cut, or hold a channel or tactic; creative and messaging direction; prospecting vs. retention | Monthly / bi-weekly | CMO, marketing managers | The strategic model's outputs translated into allocation (incrementality and marginal returns) |
| Operational | Campaign budgets, bids, creative tests, audience tests, reacting to pacing | Daily / hourly | Hands-on platform owners | Causal Attribution for granular texture, anchored by Incrementality Testing |
The point is not that strategy matters more than operations. It is that they are different decisions on different clocks, and a single instrument cannot serve all three - any more than a telescope and a microscope can share one lens.
The prize is incrementality, not attribution
The only question that ultimately matters is the counterfactual : what would have happened if the marketing had not run? Attribution never builds a counterfactual; it allocates credit within the world that happened. That is why a channel can post a brilliant attributed return while adding almost nothing incrementally.
Incrementality is the outcome with the marketing minus the outcome that would have occurred without it. Not the sales that touched an ad, and not the sales a platform claims - the sales that exist because of the marketing and would not exist otherwise.
Branded search is the classic case: a customer who already intends to buy types your brand name into a search engine, clicks your ad, and converts. Last-click attribution credits the campaign with the sale, but the ad merely intercepted a journey that was already heading to a purchase. Optimize to attributed numbers and you systematically over-invest in demand you would have captured anyway, and under-invest in genuine demand generation.
This is the shared purpose that unites all three methods: each is, at bottom, a different strategy for estimating that invisible counterfactual. An experiment builds it from a control group. An MMM builds it statistically, asking what the model predicts at zero spend. Attribution builds none on its own - which is precisely why it needs the other two.
Why the methods disagree - and why that is expected
The most common reason measurement programs lose credibility is a misunderstanding. A fresh experiment reports that a channel is driving 1.9x right now. The marketing mix model insists it is worth 2.9x. The room concludes that one of them must be broken.
Neither is broken. A regression coefficient is an average over the whole estimation window - true overall and rarely true at any single moment, like a road trip that averaged 50 mph while touching that speed for only seconds. An experiment measures a single point on that same moving curve: its value today. The model reports the multi-year average; the experiment reports the present moment. Of course they differ.
A point-in-time experiment and a multi-year average are measuring the same channel at different time scales. Disagreement is the expected result, not a defect. The skill is reading each as what it is, not forcing them to confess a single number.
Recognizing this is the difference between "our models contradict each other" and "our models describe the same business at different time scales." The second sentence is the seed of Unified Marketing Measurement.
Triangulation is orchestration, not comparison
The familiar triangle of Attribution, MMM, and Experiments is almost universally misread as "line up three numbers and check they agree." You should not expect them to agree, and comparison alone is not worth building a system around - you could do that in a spreadsheet.
The real idea is to wire the three methods together so each strengthens the others:
➡️ Experiments are the closest thing to causal ground truth, so their results flow outward to calibrate both MMM and Attribution, anchoring the statistical models to a hard causal reading.
➡️ MMM sees the whole board, so it generates the hypotheses worth testing (telling you which channel most deserves your scarce testing bandwidth) and deduplicates the attribution numbers, stripping out the double-counting platform reporting is riddled with.
➡️ Causal Attribution supplies the granular, operational texture - the ad-set- and creative-level signal - that neither strategic method can produce, and its sudden swings surface fresh hypotheses worth testing.
This integration is what we call measurement orchestration, and it only works when all three methods share one data foundation. An experiment can calibrate an MMM only if its result can flow automatically into the model's next refresh; MMM can deduplicate attribution only if both are computed on the same underlying events. Stitch three separate vendors together and you get back the spreadsheet - three numbers to compare, and none of the arrows. The integration is the product; the three methods are its ingredients.
Triangulation is the principle; orchestration is the practice. It is the difference between owning three instruments and running one system.